Taulukot, regexpit, faktorit ja joinit
aurelius
2019-05-15 11:57:39
Correct answers: h19_k4
1.1. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Tee taulukko jossa F-kirjaimella alkavien maiden osalta datassa olevat vuodet. Malli taulukosta alla
library(dplyr)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat %>%
filter(grepl("^F", cname)) %>%
count(cname)## # A tibble: 4 x 2
## cname n
## <chr> <int>
## 1 Fiji 73
## 2 Finland 73
## 3 France (-1962) 73
## 4 France (1963-) 73# Or
dat %>%
filter(grepl("^F", cname)) %>%
group_by(cname) %>%
summarise(n = n())## # A tibble: 4 x 2
## cname n
## <chr> <int>
## 1 Fiji 73
## 2 Finland 73
## 3 France (-1962) 73
## 4 France (1963-) 731.2. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Valitse undp_hdi muuttuja, poista puuttuvat arvot ja tee taulukko jossa A-kirjaimella alkavien maiden osalta datassa olevien vuosien määrä. Alla mallitaulukko.
library(dplyr)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat %>%
filter(grepl("^A", cname),
!is.na(undp_hdi)) %>%
count(cname)## # A tibble: 11 x 2
## cname n
## <chr> <int>
## 1 Afghanistan 16
## 2 Albania 28
## 3 Algeria 28
## 4 Andorra 18
## 5 Angola 19
## 6 Antigua and Barbuda 13
## 7 Argentina 28
## 8 Armenia 26
## 9 Australia 28
## 10 Austria 28
## 11 Azerbaijan 23# Or
dat %>%
filter(grepl("^F", cname),
!is.na(undp_hdi)) %>%
group_by(cname) %>%
summarise(n = n())## # A tibble: 3 x 2
## cname n
## <chr> <int>
## 1 Fiji 28
## 2 Finland 28
## 3 France (1963-) 281.3. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Tee taulukko jossa y-kirjaimeen loppuvien maiden korkein undp_hdi-arvo ja ko. vuosi.
library(dplyr)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat %>%
filter(grepl("y$", cname)) %>%
group_by(cname) %>%
filter(undp_hdi == max(undp_hdi, na.rm = TRUE)) %>%
select(cname,undp_hdi,year) %>%
ungroup()## # A tibble: 9 x 3
## cname undp_hdi year
## <chr> <dbl> <int>
## 1 Germany 0.936 2017
## 2 Hungary 0.838 2017
## 3 Italy 0.88 2017
## 4 Norway 0.953 2017
## 5 Paraguay 0.702 2015
## 6 Paraguay 0.702 2016
## 7 Paraguay 0.702 2017
## 8 Turkey 0.791 2017
## 9 Uruguay 0.804 20171.4. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Tee taulukko jossa o-kirjaimeen loppuvien maiden tuorein wdi_homicides-arvo ja ko. vuosi.
library(dplyr)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat %>%
select(cname,year,wdi_homicides) %>%
filter(!is.na(wdi_homicides),
grepl("o$", cname)) %>%
group_by(cname) %>%
filter(year == max(year, na.rm = TRUE)) %>%
select(cname,wdi_homicides,year) %>%
ungroup()## # A tibble: 10 x 3
## cname wdi_homicides year
## <chr> <dbl> <int>
## 1 Congo 9.32 2015
## 2 Lesotho 41.2 2015
## 3 Mexico 19.3 2016
## 4 Monaco 0 2015
## 5 Montenegro 4.46 2016
## 6 Morocco 1.24 2015
## 7 San Marino 0 2011
## 8 Togo 9.00 2015
## 9 Trinidad and Tobago 30.9 2015
## 10 Burkina Faso 0.370 20151.5. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Tee taulukko jossa d-kirjaimeen loppuvien maiden osalta top3 maat muuttujan wdi_internet-suhteen paremmuusjärjestyksessä kunakin vuonna 2014,2015,2016 ja 2017.
library(dplyr)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat %>%
select(cname,year,wdi_internet) %>%
filter(!is.na(wdi_internet),
grepl("d$", cname),
year %in% 2014:2017) %>%
group_by(year) %>%
arrange(desc(wdi_internet)) %>%
slice(1:3) %>%
ungroup()## # A tibble: 12 x 3
## cname year wdi_internet
## <chr> <int> <dbl>
## 1 Iceland 2014 98.2
## 2 Switzerland 2014 87.4
## 3 Finland 2014 86.5
## 4 Iceland 2015 98.2
## 5 New Zealand 2015 88.2
## 6 Switzerland 2015 87.5
## 7 Iceland 2016 98.2
## 8 Switzerland 2016 89.1
## 9 New Zealand 2016 88.5
## 10 Switzerland 2017 93.7
## 11 Finland 2017 87.5
## 12 Ireland 2017 84.51.6. Käsitellään dplyr-paketin Starwars dataa. Miten valitse hahmot, joiden nimessä on --merkki
dplyr::starwars %>% filter(grepl('-', name))## # A tibble: 8 x 13
## name height mass hair_color skin_color eye_color birth_year gender
## <chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
## 1 C-3PO 167 75 <NA> gold yellow 112 <NA>
## 2 R2-D2 96 32 <NA> white, bl… red 33 <NA>
## 3 R5-D4 97 32 <NA> white, red red NA <NA>
## 4 Obi-… 182 77 auburn, w… fair blue-gray 57 male
## 5 IG-88 200 140 none metal red 15 none
## 6 Qui-… 193 89 brown fair blue 92 male
## 7 Ki-A… 198 82 white pale yellow 92 male
## 8 R4-P… 96 NA none silver, r… red, blue NA female
## # … with 5 more variables: homeworld <chr>, species <chr>, films <list>,
## # vehicles <list>, starships <list>1.7. Käsitellään dplyr-paketin Starwars dataa. Valitse hahmot joiden kotimaailman nimi on kaksiosainen Ja laske hahmojen määrät kotimaailmoittain
dplyr::starwars %>%
filter(grepl(" ", homeworld)) %>%
count(homeworld)## # A tibble: 8 x 2
## homeworld n
## <chr> <int>
## 1 Aleen Minor 1
## 2 Bestine IV 1
## 3 Cato Neimoidia 1
## 4 Concord Dawn 1
## 5 Glee Anselm 1
## 6 Haruun Kal 1
## 7 Mon Cala 1
## 8 Nal Hutta 11.8. Käsitellään dplyr-paketin Starwars dataa. Luo uusi muuttuja eye_color_base, jossa on eye_color-muuttujan arvon ensimmäinen väri (blue-gray -> blue)! Valitse lopuksi vain hahmot joilla on kaksiosaisen silmien väri ja muuttujat name, eye_color, eye_color_base
dplyr::starwars %>%
mutate(eye_color_base = gsub('-.+$|,.+$', "", eye_color)) %>%
filter(grepl("-|,", eye_color)) %>%
select(name,eye_color,eye_color_base)## # A tibble: 3 x 3
## name eye_color eye_color_base
## <chr> <chr> <chr>
## 1 Obi-Wan Kenobi blue-gray blue
## 2 R4-P17 red, blue red
## 3 Grievous green, yellow green1.9. Suomen kekkosenjälkeiset presidentit ovat olleet Ahtisaari, Halonen, Koivisto ja Niinistö. Tee sukunimistä faktori, jonka leveleissä ne asetetaan järjestykseen kausien mukaan. (ekaksi koivisto)
factor(c("Ahtisaari","Halonen","Koivisto","Niinistö"),
levels = c("Koivisto","Ahtisaari","Halonen","Niinistö"))## [1] Ahtisaari Halonen Koivisto Niinistö
## Levels: Koivisto Ahtisaari Halonen Niinistö1.10. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Miten saat seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/h19_k4_factor_2.png
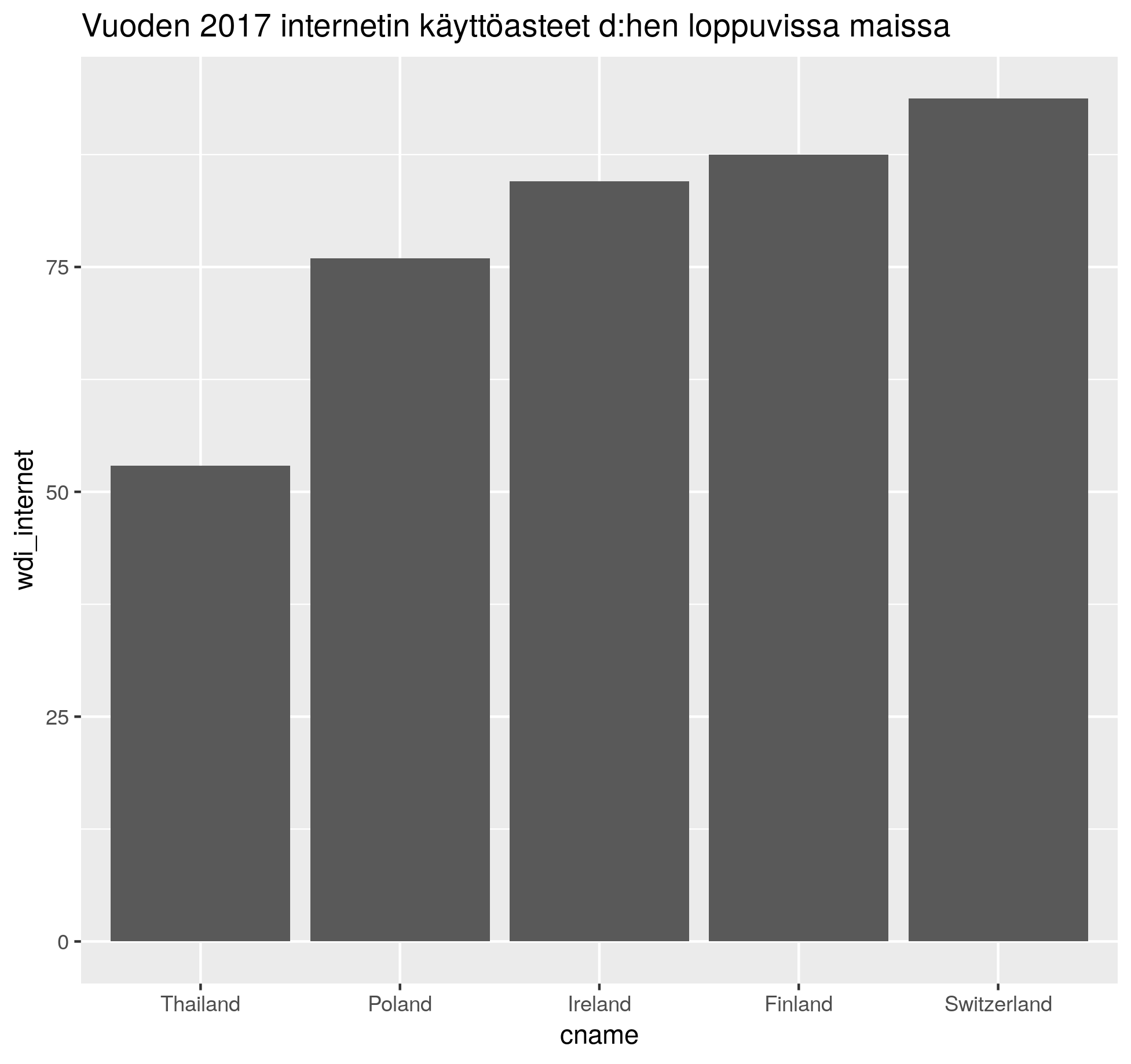{kind=link}
library(dplyr)
library(ggplot2)
library(forcats)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
kuvadata <- dat %>%
select(cname,year,wdi_internet) %>%
filter(!is.na(wdi_internet),
grepl("d$", cname),
year %in% 2017) %>%
mutate(cname = fct_reorder(cname, wdi_internet))
ggplot(kuvadata, aes(x = cname, y = wdi_internet)) +
geom_col() +
labs(title = "Vuoden 2017 internetin käyttöasteet d:hen loppuvissa maissa")
1.11. “Pura” starwars-datan films-muuttujan “sisäkkäisyys” (nested) seuraavalla koodilla: dplyr::starwars %>% tidyr::unnest(films) %>% select(name,gender,films) Miten saat ko. datasta seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/h19_k4_factor_3.png
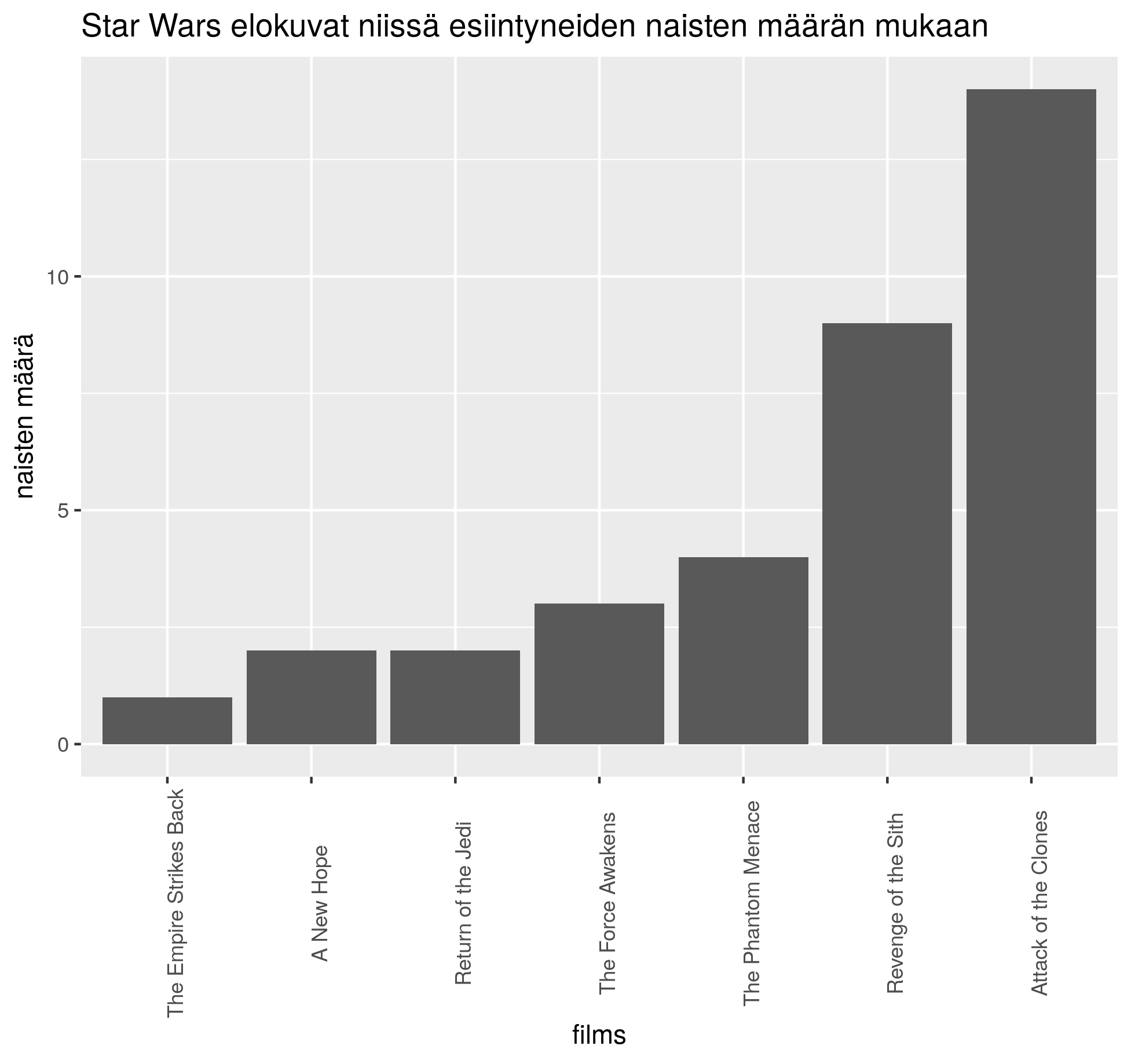{kind=link}
library(dplyr)
library(ggplot2)
library(forcats)
library(tidyr)
kuvadata <- dplyr::starwars %>%
unnest(films) %>%
select(name,gender,films) %>%
group_by(films) %>% count(gender) %>%
filter(gender == "female") %>%
ungroup() %>%
mutate(films = fct_reorder(films, n))
p <- ggplot(kuvadata, aes(x = films, y = n)) +
geom_col() +
labs(title = "Star Wars elokuvat niissä esiintyneiden naisten määrän mukaan", y = "naisten määrä") +
theme(axis.text.x = element_text(angle = 90))1.12. “Pura” starwars-datan films-muuttujan “sisäkkäisyys” (nested) seuraavalla koodilla: dplyr::starwars %>% tidyr::unnest(films) %>% select(name,gender,films) Miten saat ko. datasta seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/h19_k4_factor_4.png
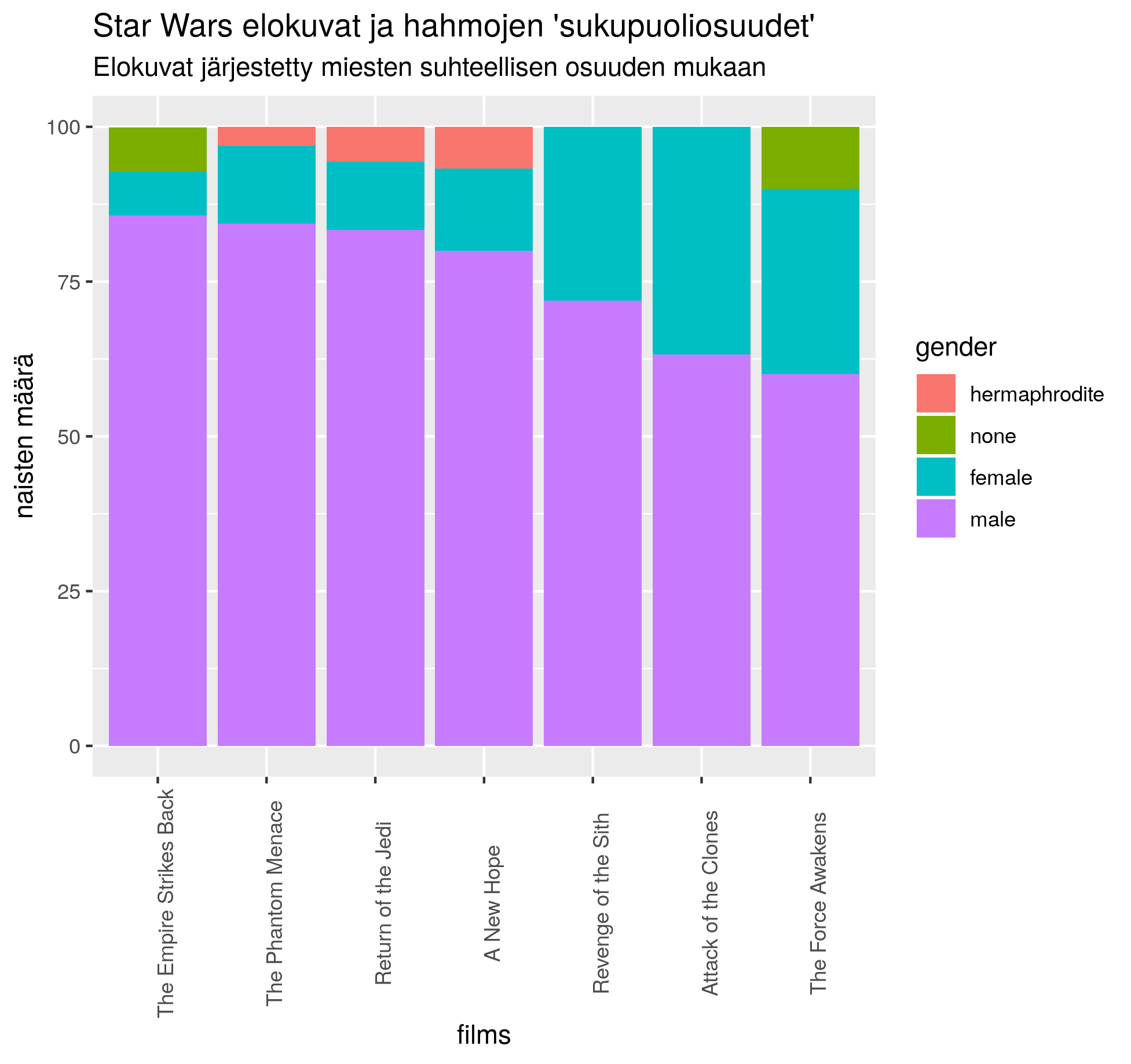{kind=link}
library(dplyr)
library(dplyr)
library(ggplot2)
library(forcats)
library(tidyr)
kuvadata <- dplyr::starwars %>%
unnest(films) %>%
select(name,gender,films) %>%
filter(!is.na(gender)) %>%
group_by(films) %>%
count(gender) %>%
mutate(osuus = round(n/sum(n)*100,1))
# suput esiintymisasteen (kaikissa elokuvissa) mukaan
suput <- kuvadata %>%
group_by(gender) %>%
summarise(osuus = sum(osuus)) %>%
arrange(desc(osuus)) %>%
pull(gender)
# elokuvat miesten esiintymisasteen mukaan
elokuvat <- kuvadata %>%
filter(gender == "male") %>%
arrange(desc(osuus)) %>%
pull(films)
# asetetaan faktorilevelit
kuvadata$gender <- factor(kuvadata$gender, levels = rev(suput))
kuvadata$films <- factor(kuvadata$films, levels = elokuvat)
ggplot(kuvadata, aes(x = films,
y = osuus,
fill = gender)) +
geom_col() +
labs(title = "Star Wars elokuvat ja hahmojen 'sukupuoliosuudet'",
subtitle = "Elokuvat järjestetty miesten suhteellisen osuuden mukaan",
y = "naisten määrä") +
theme(axis.text.x = element_text(angle = 90))
1.13. Asenna CRAN:sta paketti nycflights13 ja lataa se. Datat on kuvattu luvussa: http://r4ds.had.co.nz/relational-data.html#nycflights13-relational - yhdistä datat flights ja airlines. Kuinka monta lentoa Hawaiian Airlines Inc. lensi John F. Kennedyn kansainväliseltä lentoasemalta (JFK) vuonna 2013. Datojen dokumentaation saa esim. komennolla ?flights
library(nycflights13)
library(dplyr)
left_join(flights, airlines) %>%
filter(name == "Hawaiian Airlines Inc.",
year == 2013,
origin == "JFK") %>%
summarise(n=n())## # A tibble: 1 x 1
## n
## <int>
## 1 3421.14. Yhdistä dataan flights datat airlines ja planes. Kuinka monta matkustajaa US Airways Inc. yhtiön lennoilla JFK:lta oli keskimäärin vuonna 2013.
library(nycflights13)
library(dplyr)
left_join(flights, airlines) %>%
left_join(planes) %>%
filter(name == "US Airways Inc.",
year == 2013,
origin == "JFK") %>%
summarise(seats = mean(seats, na.rm = TRUE))## # A tibble: 1 x 1
## seats
## <dbl>
## 1 258.1.15. Yhdistä dataan flights data airports ja weather. Montako sellaista lentoa kentältä JFK:n kentältä lähti vuonna 2013 jolloin tuulennopeus >= 30?
library(nycflights13)
library(dplyr)
left_join(flights, airports, by = c("origin" = "faa")) %>%
left_join(weather) %>%
filter(origin == "JFK",
year == 2013,
wind_speed >= 30) %>%
count()## # A tibble: 1 x 1
## n
## <int>
## 1 5071.16. dplyr-paketin mukana tulee data storms. Tallenna se työhakemistoon RDS muodossa. Miten luet datan takaisin R:ään?
saveRDS(storms, "./storms.RDS")
storms <- readRDS("./storms.RDS")1.17. dplyr-paketin mukana tulee data storms. Tallenna se työhakemistoon csv muodossa. Miten luet datan takaisin R:ään?
write.csv(storms, "./storms.csv")
storms <- read.csv("./storms.csv", stringsAsFactors = FALSE)1.18. dplyr-paketin mukana tulee data storms. Tallenna se työhakemistoon xlsx muodossa. Miten luet datan takaisin R:ään?
openxlsx::write.xlsx(storms, "./storms.xlsx")
readxl::read_excel("./storms.xlsx")## # A tibble: 10,010 x 14
## X name year month day hour lat long status category wind
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 1 Amy 1975 6 27 0 27.5 -79 tropi… -1 25
## 2 2 Amy 1975 6 27 6 28.5 -79 tropi… -1 25
## 3 3 Amy 1975 6 27 12 29.5 -79 tropi… -1 25
## 4 4 Amy 1975 6 27 18 30.5 -79 tropi… -1 25
## 5 5 Amy 1975 6 28 0 31.5 -78.8 tropi… -1 25
## 6 6 Amy 1975 6 28 6 32.4 -78.7 tropi… -1 25
## 7 7 Amy 1975 6 28 12 33.3 -78 tropi… -1 25
## 8 8 Amy 1975 6 28 18 34 -77 tropi… -1 30
## 9 9 Amy 1975 6 29 0 34.4 -75.8 tropi… 0 35
## 10 10 Amy 1975 6 29 6 34 -74.8 tropi… 0 40
## # … with 10,000 more rows, and 3 more variables: pressure <dbl>,
## # ts_diameter <lgl>, hu_diameter <lgl>1.19. dplyr-paketin mukana tulee data storms. Tallenna se työhakemistoon SPSS:n .sav muodossa. Miten luet datan takaisin R:ään?
haven::write_sav(storms, "./storms.sav")
storms <- haven::read_sav("./storms.sav")1.20. dplyr-paketin mukana tulee data storms. Tallenna se työhakemistoon käyttämäsi tilasto-ohjelman formaatissa SEKÄ .csv-muodossa. Saatko luettua ko. tiedostot ko. tilasto-ohjelmaan?
# saan!
#' *1.21. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019) ). Miten saat seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/visu_h19_k4_1.png*
#'
#+ h19_k4_visu_h19_k4_1_answer, eval = TRUE
library(dplyr)
library(ggplot2)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat2 <- dat %>%
select(year,cname,wdi_homicides) %>%
filter(!is.na(wdi_homicides),
grepl("o$", cname))
ggplot(dat2, aes(x = year,
y = wdi_homicides,
color = cname)) +
geom_point() +
geom_line() +
theme(legend.position = "none") +
geom_text(data = dat2 %>%
group_by(cname) %>%
filter(year == max(year, na.rm = TRUE)) %>%
ungroup(),
aes(label = cname))
1.22. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Miten saat seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/visu_h19_k4_2.png
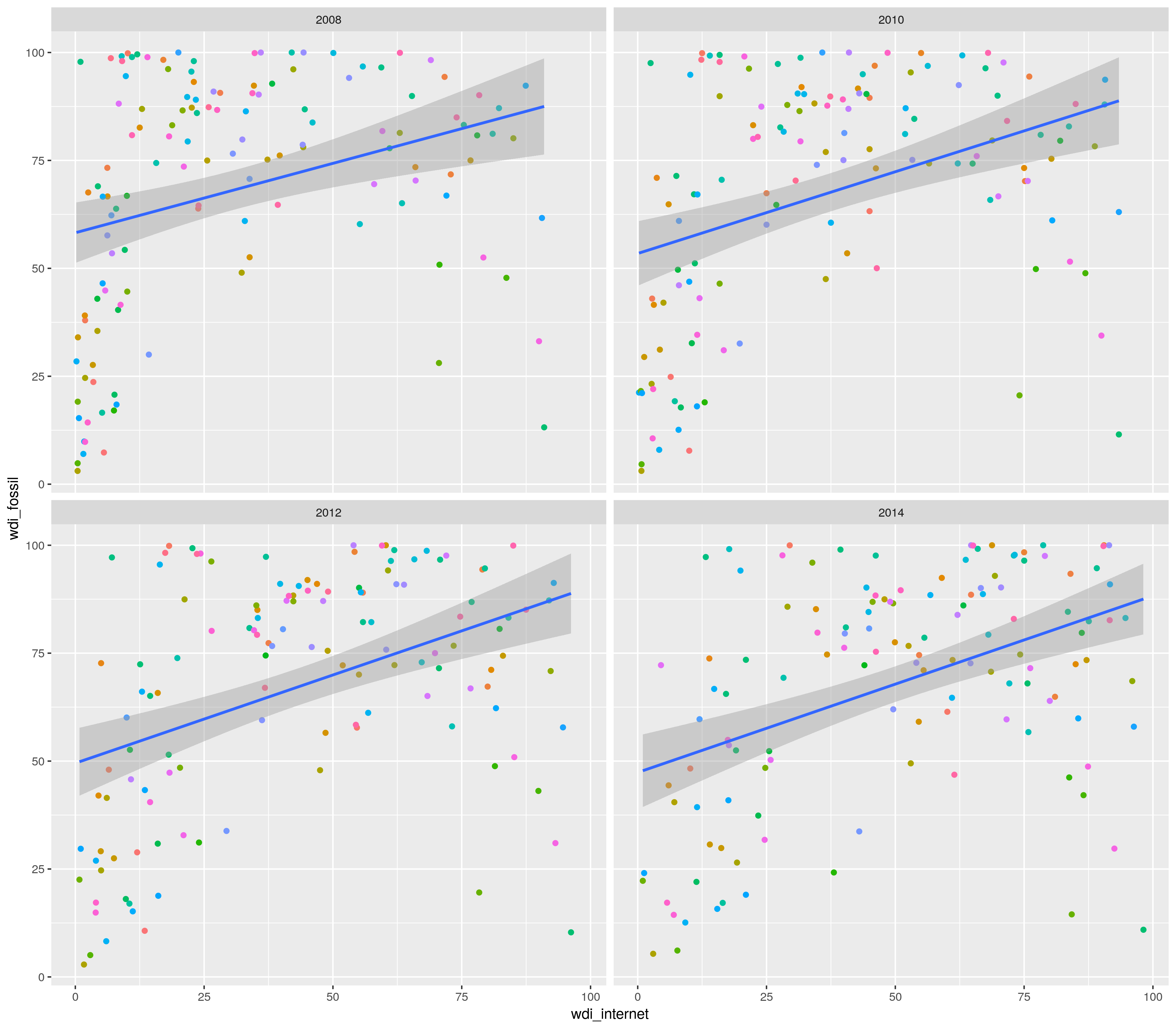{kind=link}
library(dplyr)
library(ggplot2)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat2 <- dat %>%
select(year,cname,wdi_internet,wdi_elerenew) %>%
filter(year %in% c(2008,2010,2012,2014))
ggplot(dat2, aes(x = wdi_internet,
y = wdi_elerenew,
color = cname,
group = 1)) +
geom_point() +
facet_wrap(~year) +
geom_smooth(method = "lm") +
theme(legend.position = "none")
1.23. Lataa QOG-projektin Basic data (dat <- rqog::read_qog(which_data = “basic”, data_type = “time-series”, year = 2019) ). Miten saat seuraavanlaisen kuvan http://courses.markuskainu.fi/utur2019/kuvat/visu_h19_k4_3.png
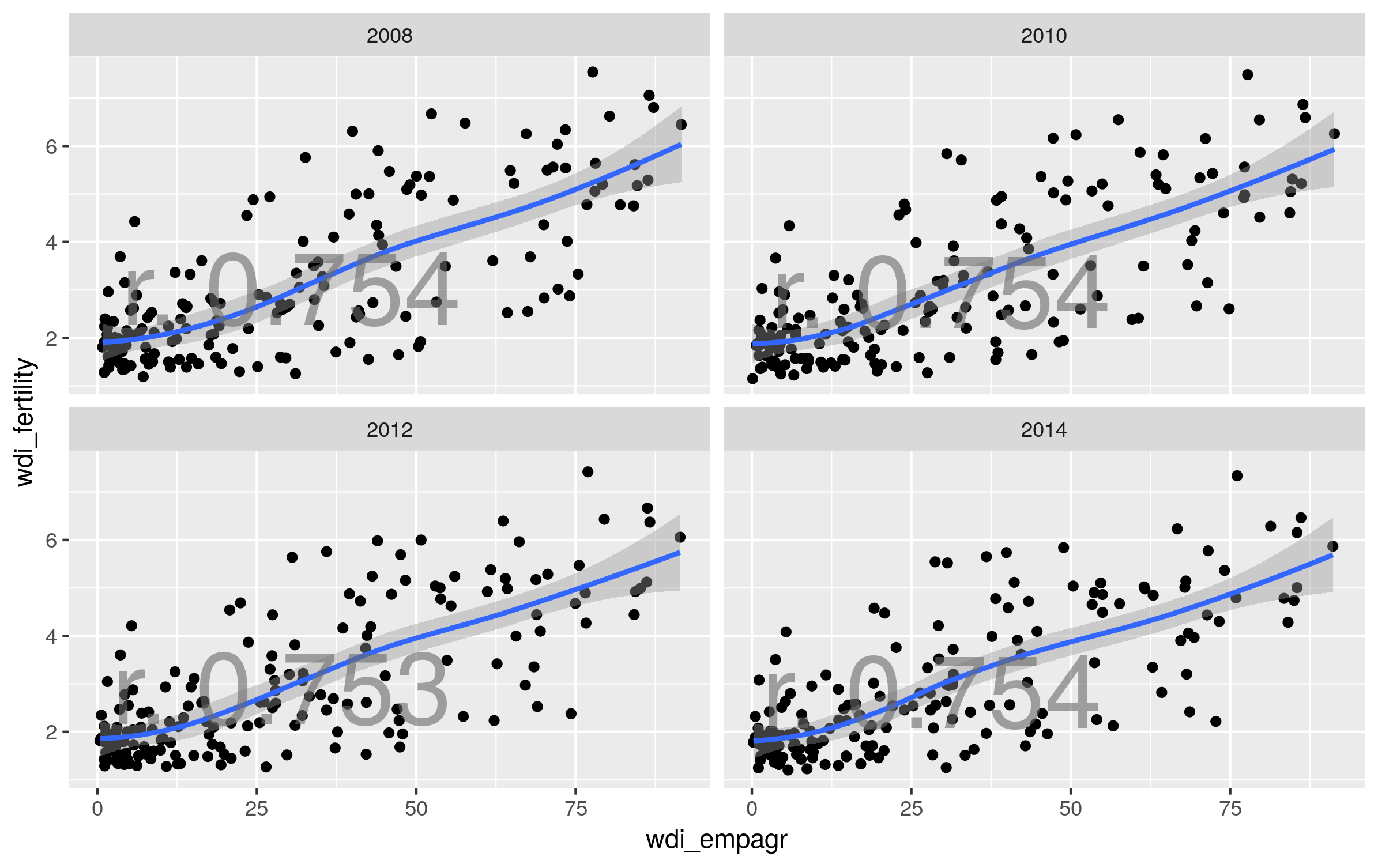{kind=link}
library(dplyr)
library(ggplot2)
dat <- rqog::read_qog(which_data = "basic", data_type = "time-series", year = 2019)
dat2 <- dat %>%
select(year,cname,wdi_fertility,wdi_empagr) %>%
filter(year %in% c(2008,2010,2012,2014))
dat_cor <- dat2 %>%
na.omit() %>%
group_by(year) %>%
summarise(corr = cor(wdi_empagr,wdi_fertility, method = "pearson"),
wdi_fertility = mean(wdi_fertility, na.rm = TRUE),
wdi_empagr = mean(wdi_empagr, na.rm = TRUE))
ggplot(dat2, aes(x = wdi_empagr,
y = wdi_fertility)) +
geom_point() +
facet_wrap(~year) +
geom_smooth() +
geom_text(data = dat_cor,
aes(label = paste0("r. ", round(corr, 3))),
color = "dim grey",
size = 25, alpha = .4)